Diagram from MasPar System Overview and MPPE Manual
MasPar Computer Corporation
MasPar stands for Massively Parallel Machine. The concept of Massively Parallel is a machine which incorperates massive amounts of processing elements. By using a Distributed Memory architecture (one which combines local memory and processor at each level of the interconnection network) we can create machines with almost an infinate number of processors without compromising design. The only thing that limits these types of computers is the cost of the processing elements.
The MasPar is a SIMD machine. That means that a single instruction operates on many different pieces of data simultaneously. The following section will explain how this occurs.
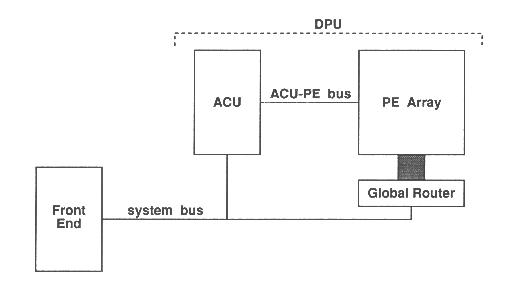
The diagram below shows how the MasPar architecture is organized. The two main parts to be concerned with are:
Diagram
from MasPar System Overview and MPPE Manual
MasPar Computer
Corporation
The machine consists of the Processing Elements (PEs) connected in a 2-D lattice. The machine is driven by a front-end computer. High speed I/O devices can be attached, and direct access to the DEC memory bus is possible. Note the PEs are custom designed by MasPar. They are RISC-like and grouped into clusters of 16 on the chips. Each cluster has the PE memories and connections to the communications network. Instructions are issued by the Array Control Unit, which is a RISC-like processor based on standard chips from Texas Instruments. Topology Grid connections allow communication to 8 nearest neighbours. Operating System Supplied is a UNIX front-end. The languages supported are an ANSI compatible C, and MasPar Fortran (MPF) which is an in-house version of Fortran 90. Programming Environment MasPar has licensed a version of the Fortran conversion package VAST-2 from Pacific-Sierra Research Corporation. This product converts from scalar Fortran 77 source code to parallel MPF source. The conversion can also be done in reverse. Performance is 1.2 GFLOPS (2.6 GIPS) for a 16384 PE machine. Data Transfer Nearest neighbour is 18 Gbyte/sec for 16384 machine, and 1300 Mbyte/sec using the global router (Manufacturers figures). Scalability Scales from 1024 -- 16384 processing elements. Fault Tolerance Manufacturers claim mean time between failures of over 8,000 hours. No fault tolerant features. Price Performance With an estimated \pounds500,000 for a 16384 processor system gives \pounds450,000 per GFLOP (using figures from PPP). User base The machine is marketed as a Grand Challenge machine due to its high reliability. The DAP 610c has a lower FLOPS rating by a factor of two for a machine with 4 time fewer processors. The installed base is small. Typical applications are DNA sequence matching and image deblurring.
Since the computational engine of the MasPar does not have an operating system of it's own, a UNIX based workstation is used to provide the programmer with a "friendly" interface to the MasPar. When MasPar programs are executed, the user process runs on the front-end while parallel code is automatically passed to the DPU for execution. Programs can be compiled and debugged on the front-end using MPPE (MasPar Programming Environment).
The DPU executes the parallel portions of a program and consists of two parts:
The ACU has two tasks
Programs written in normal C and Fortran are executed on the front-end machine. These programs can contain procedures written in MPL (MasPar Programming Language) or MPF. When these procedures are called, they are executed entirely inside the DPU. Executing entirely in the DPU is an advantage in the sense that the code is slightly simpler in terms of design. However, sequential code segments will probably perform poorly due to the limited processing capability of the processor inside the ACU. Depending on the amount of sequential code in the entire program, it may or may not pay off to run it entirely in the DPU.
Parallel operations on parallel (plural) data are executed in the DPU as follows. The ACU broadcasts each instruction to all PE's in the PE Array. Each PE in the array then executes the instruction simultaneously, manipulating each PE's copy of the plur al (parallel) data.
Programs written using MPL are executed as above except for the following. The ACU fetches and decodes all program instructions during its execution. When an instruction that operates on singular data is encountered, the ACU simply executes the instruct ion locally on its own processor. When an instruction operating on plural data is decoded, it is processed as described above. The front-end processor does not execute any code in this case.
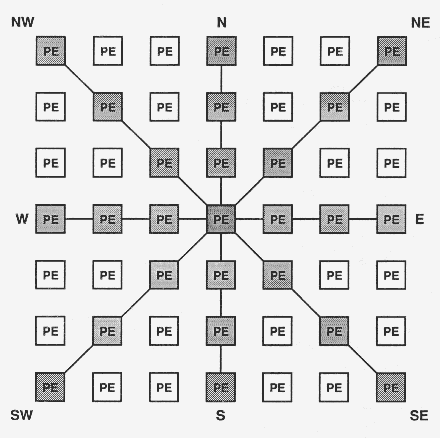
The PE Array is a 2D mesh of relatively simple processors (PEs). Each processor is connected to all eight of its neighbors as shown in the diagram below. The connectio ns at the edges of the mesh wrap around to form a torus shaped network.
Diagram
from MasPar System Overview and MPPE Manual
MasPar Computer
Corporation
Each PE is capable of reading and writing memory and performing arithmetic operations. The PEs are not able to fetch or decode instructions; they can only execute instructions. Each PE has 16K of RAM and forty 32-bit registers.
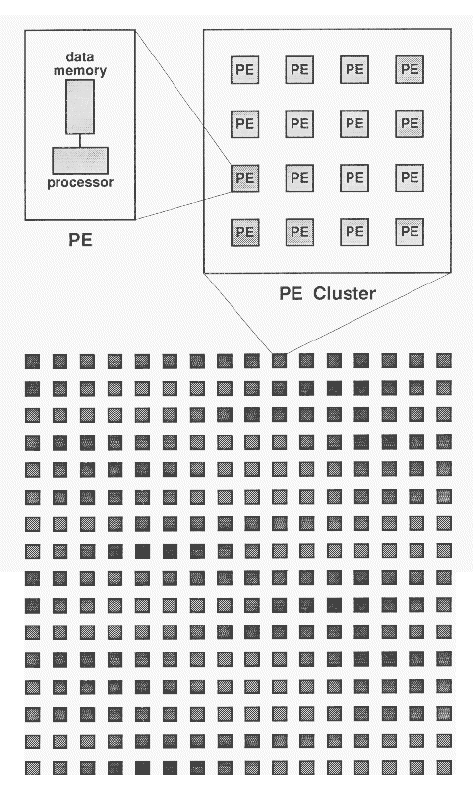
The 2D mesh of PEs is divided up into 4 x 4 clusters of processors. The diagram below illustrates how clusters and PEs are related.
Diagram
from MasPar System Overview and MPPE Manual
MasPar Computer
Corporation
An important point to remember is that each PE in a cluster shares a common global communications channel (a crossbar switch). This is important because bottlenecks can arise when massive amounts of inter-cluster global routing is used for communication.